First step to the world of AI: installing a local LLM
After a long time, I've decided to embark on my journey with AI. Over this period, significant progress has been made in the field. Today, we're surrounded by numerous Large Language Model (LLM) models, tools, and agents. It's therefore timely to prepare for the next big things. To begin, let me provide a brief overview of key AI terminology.
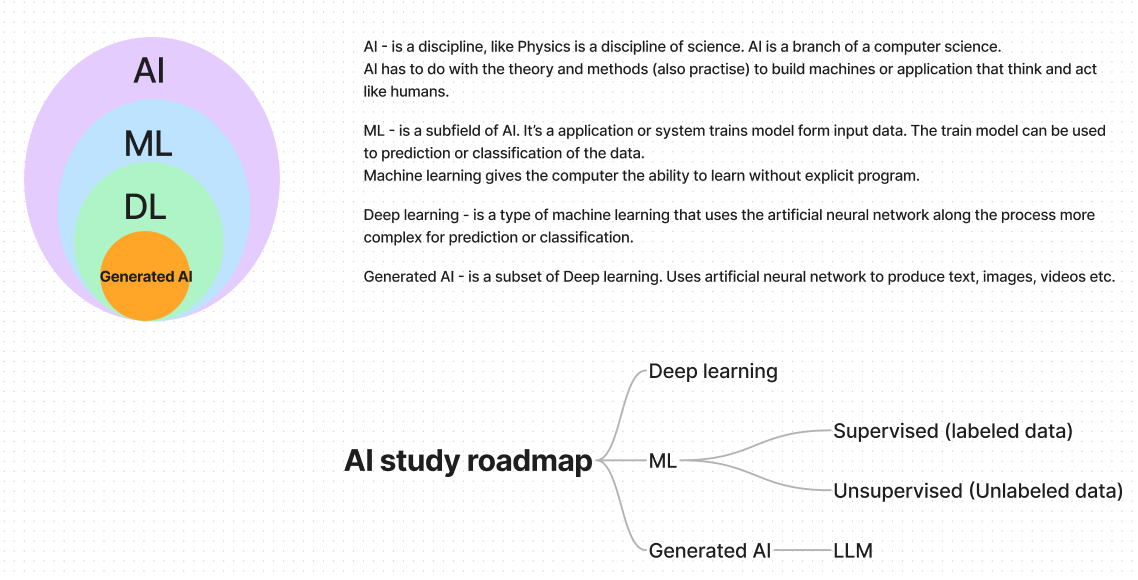
For my study roadmap, I plan to utilize a Local Large Language Model (LLM) installed on my home lab server. Currently, there are several LLM models available for local use. I will be using Meta's LLaMA 3 model. Below is my server configuration:
Server: promox virtual server (Ubuntu)
CPU : 16 vcpu
RAM: 16 gb
LLM: Llama 3 8B parameters
LLM running platform: Ollama
Web and desktop client: Open WebUI and AnythingLLM
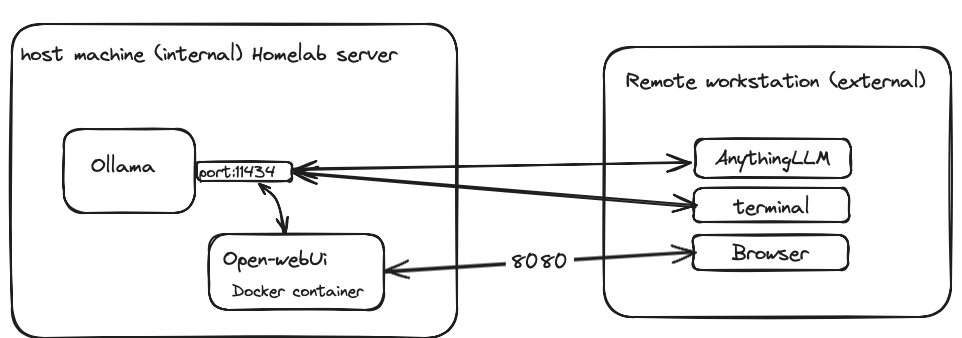
A few words about Ollama, Ollama is an open-source project that enables running Large Language Model (LLM) models locally. It provides both Command-Line Interface (CLI) and Application Programming Interface (API) for interaction. With Ollama, you can run a wide range of LLM models, including popular ones like LLaMA 3, Gemma, Mistrals, and more.
Step 1. Install Ollama.
To get started, run the following command to download and install Ollama.
curl -fsSL https://ollama.com/install.sh | shTo verify that Ollama is up and running, simply visit the following URL in any web browser.
http://localhost:11434 It should return "ollama is running"
Important note: by default, Ollama does not use your local IP address. Instead, it will be accessible through localhost (127.0.0.1) or loopback addresses. If you want to access Ollama from a remote machine like mine, follow these steps:
Step 2 (optional). Configure the ollama server. This step is not necessary if you are using Ollama version 0.1.48 or later.
Edit the /etc/systemd/system/ollama.service file as shown below
sudo nano /etc/systemd/system/ollama.serviceAdd the following environment parameter.
Environment="OLLAMA_HOST=0.0.0.0”Reload systemd and restart Ollama as follows:
systemctl daemon-reload systemctl restart ollamaNow, you can access the ollama server from the remote machines by it's ip address.
Step 3 (Optional). Stop and confirm the server status
# stop the ollama servicesystemctl stop ollama.service# confirm the server statussystemctl status ollama.serviceStep 4. Pull and run a LLM model.
Now that Ollama is up and running, you can start using it to run models. Before doing so, make sure to pull the model first by running the following command on any terminal.
ollama pull llama3
ollama run llama3Downloading and running the Large Language Model (LLM) may take a few minutes, depending on your internet speed. Once the download is complete, you should see a command-line prompt as shown below, which allows you to interact with LLaMA 3.
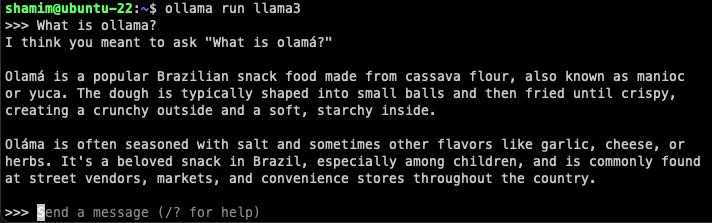
Let's ask "what is Ollama?"
The answer is very interesting.
Once everything is set up locally, you can use Ollama without an internet connection. However, interacting with Ollama through the terminal command line may not be as user-friendly, and chat history will not be saved for future reference. For a more intuitive experience, there are web-based UIs and standalone applications that allow interaction with remote Ollama servers, offering features like RAG or agents.
In our next installment of this series, I'll demonstrate how to install Open-webUI and AnythingLLM and use them with the Ollama server.