Bootstrapping а PostgreSQL logical replication application
Recently I was involved into a project for replicating data from PostgreSQL to Datalake. I heard about PostgreSQL logical data replication a few years ago and found a few hours to play with the Change data capture function of these popular database. Today's blog is all about PostgreSQL logical replication with a few fragments of code to test the functionality.
Change data capture is an architecture design principle that allows us to capture the recently data changed into the database in realtime. The changes could be any DML operations: Insert, update, delete. There are a few characteristics of CDC as follow:
Logical replication uses publish-subscribe model. Subscriber pulls the data from the publication they subscribe to and manipulate the data.
Only commited transactions on WAL archive (transaction log file) will be return by the CDC.
CDC will return on orderd form how they commited on the database.
Logical CDC doesn't impact on database performance.
From the PostgreSQL v15, you can get the logical changes from specific table rows/columns
You can use a several output plugins to get the data into different formats such as JSON, AVRO, Binary etc.

Note that, you can't use PostgreSQL logical and physical replication at the same time. The difference between physical replication and logical replication is that logical replication sends data over in a logical format whereas physical replication sends data over in a binary format.
Before dive into the PostgreSQL logical replication, it will be useful to understand a few concepts:
Publication. From the PostgreSQL documentation: A publication is a set of changes generated from a table or a group of tables, and might also be described as a change set or replication set. Each publication exists in only one database.
Every publication can have multiple subscribers.
A publication is created using the CREATE PUBLICATION command and may later be altered or dropped using corresponding commands.
Logical decoding. From the PostgreSQL manual, "Logical decoding is the process of extracting all persistent changes to a database's tables into a coherent, easy to understand format which can be interpreted without detailed knowledge of the database's internal state." Transaction Log or the WAL archive format is binary and can change over time. Also, the WAL contains changes for every database in the server. Here logical decoding comes into play by providing changes only one database per slot through API with facilities to writing into an output plugin, which can return the data into any format you define.
Replication slot. A replication slot is a sequence of changes that happened on the database. The slot manages the set of changes and sent through the plugin. There can be more than one slot in the database. PostgreSQL provides a set of FUNCTIONS and VIEWS for working with the Replication slot such as pg_create_logical_replication_slot or pg_replication_slots.
Output Plugin. A plugin is a library written in different programming languages, which accepts the changes and decodes the changes into a format you preferred. Plugins need to be compiled and installed before uses. Here is the list of all available plugins for PostgreSQL.
Now, let's try to develop a simple Java Application to try all the concepts we have learn before. What are we going to do?
Configure the database.
Develop a Java application to use the PostgreSQL Replication API to change data capture.
Java application will use the "test_decoding" output plugin to print the changes into the console.
Also, we will try the pGEasyRepliction project to get the CDC into JSON format.
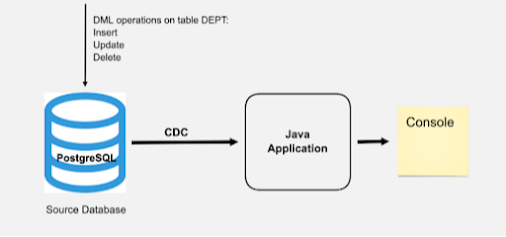
Step 1. Configure the database.
Enable the logical replication of the PostgreSQL database into the postgresql.conf file as shown below:
max_wal_senders = 4 # max number of walsender processes
wal_keep_segments = 4 # in logfile segments, 16MB each; 0 disables
wal_level = logical # minimal, replica, or logical
max_replication_slots = 4 # max number of replication slotsIf you are using docker like me to up and running PostgreSQL DB, open a bash shell inside the docker container as follows:
sudo docker exec -it <container-id> /bin/bashEdit the postgresql.conf file with vi editor.
bash-5.0# vi var/lib/postgresql/data/postgresql.confIf you don't installed vi editor in the docker container, you have to install it. Install the vi editor inside the container as shown below:
apt-get update
apt-get install vimEdit the postgresql.conf file and exit the bash and the container.
Then, restart the docker container with the following commands.
sudo docker restart <container-name>Allow replication connections from local network and set the replication privileges into the pg_hba.conf file as follows:
local replication all trust
host replication all 127.0.0.1/32 md5
host replication all ::1/128 md5Step 2. Create two tables by the following DDL script.
create table dept(
deptno integer,
dname text,
loc text,
constraint pk_dept primary key (deptno)
);
create table emp(
empno integer,
ename text,
job text,
mgr integer,
hiredate date,
sal integer,
comm integer,
deptno integer,
constraint pk_emp primary key (empno),
constraint fk_deptno foreign key (deptno) references dept (deptno)
);
CREATE UNIQUE INDEX ename_idx ON emp (ename);Step 3. Add a few rows into the tables.
insert into dept
values(10, 'ACCOUNTING', 'NEW YORK');
insert into dept
values(20, 'RESEARCH', 'DALLAS');
insert into dept
values(30, 'SALES', 'CHICAGO');
insert into dept
values(40, 'OPERATIONS', 'BOSTON');
insert into emp
values(
7839, 'KING', 'PRESIDENT', null,
to_date('17-11-1981','dd-mm-yyyy'),
5000, null, 10
);
insert into emp
values(
7698, 'BLAKE', 'MANAGER', 7839,
to_date('1-5-1981','dd-mm-yyyy'),
2850, null, 30
);
insert into emp
values(
7782, 'CLARK', 'MANAGER', 7839,
to_date('9-6-1981','dd-mm-yyyy'),
2450, null, 10
);
insert into emp
values(
7566, 'JONES', 'MANAGER', 7839,
to_date('2-4-1981','dd-mm-yyyy'),
2975, null, 20
);
insert into emp
values(
7788, 'SCOTT', 'ANALYST', 7566,
to_date('13-07-87','dd-mm-rr') - 85,
3000, null, 20
);Step 4. Create a standalone Java application project. You can use your favoutite IDE or Maven/Gradle to build, compile and run the application. The entire project is located on Github.
First, we have create a database connection in replication mode. In this mode, the connection is not available for execute SQL statements.
InputStream is = new FileInputStream(rootPath+"application.properties");//PostgreSQLConsumer.class.getResourceAsStream(rootPath+"application.properties");
Properties config = new Properties();
config.load(is);
Properties props = new Properties();
PGProperty.USER.set(props, config.getProperty("db.user"));
PGProperty.PASSWORD.set(props, config.getProperty("db.password"));
PGProperty.ASSUME_MIN_SERVER_VERSION.set(props, "9.4");
PGProperty.REPLICATION.set(props, "database");
PGProperty.PREFER_QUERY_MODE.set(props, "simple");
Connection con = DriverManager.getConnection(config.getProperty("db.url"), props);
PGConnection replConnection = con.unwrap(PGConnection.class);In the above fragments of the code, we are reading the database connection properties from the application.properties file
db.url=jdbc:postgresql://localhost:5432/postgres
db.user=postgres
db.password=postgres
repl.logical.slot=10Step 5. Create a Replication slot via API
replConnection.getReplicationAPI()
.createReplicationSlot()
.logical()
.withSlotName("demo_logical_slot_"+ config.getProperty("repl.logical.slot"))
.withOutputPlugin("test_decoding")
.make();Note that, you can also create replication slot by SQL statements as shown below.
#Create a publication that publishes all changes in all tables:
CREATE PUBLICATION alltables FOR ALL TABLES;
#Create a publication that publishes all changes for table DEPT, but replicates only columns deptno and dname:
CREATE PUBLICATION DEPT_filtered FOR TABLE users (deptno, dname);Step 6. Create a Replication Stream pragmatically .
PGReplicationStream stream =
replConnection.getReplicationAPI()
.replicationStream()
.logical()
.withSlotName("demo_logical_slot_"+ config.getProperty("repl.logical.slot"))
.withSlotOption("include-xids", true)
.withSlotOption("skip-empty-xacts", true)
.withStatusInterval(20, TimeUnit.SECONDS)
.start();The above replication stream will send the changes since the creation of the replication slot.
Step 7. Recieve CDC event for further processing as follows:
while (true) {
ByteBuffer msg = stream.readPending();
if (msg == null) {
TimeUnit.MILLISECONDS.sleep(10L);
continue;
}
int offset = msg.arrayOffset();
byte[] source = msg.array();
int length = source.length - offset;
logger.info(new String(source, offset, length));
//feedback by LOG sequence Number
stream.setAppliedLSN(stream.getLastReceiveLSN());
stream.setFlushedLSN(stream.getLastReceiveLSN());
}The above fragment of the code will receive the CDC and print the event on console. Open the PostgreSQL SQL editor and execute the following SQL query:
INSERT INTO public.dept (deptno,dname,loc) VALUES
(144,'RESEARCH1','DALLAS1');
update public.dept set dname='refresh' where deptno =144;
delete from public.dept where deptno = 144;
commit;The output should looks like these:
BEGIN 779
table public.dept: INSERT: deptno[integer]:144 dname[text]:'RESEARCH1' loc[text]:'DALLAS1'
table public.dept: UPDATE: deptno[integer]:144 dname[text]:'refresh' loc[text]:'DALLAS1'
table public.dept: DELETE: deptno[integer]:144
COMMIT 779The "test_decoding" output plugin is very usefull as a starting point. You can install output plugin you prefered such as JSON, AVRO and continue develop your application.
See the resource section to get the list of all plugins availabe for PostgreSQL. Moreover, I forked the pgEasyReplication project from the GitHub which can return the CDC events into JSON format. The library is very easy to use. For more information, see the App.Java class to learn how to use the library.
Now, what to do if you are using JSON or JSONB in PostgreSQL? How to filter row by JSON fields?
Good news is that, from the 14th version, PostgreSQL replication slot supports JSONB. So let's try a few more example to check these possibilities.
Step 8. Create a simple table with JSONB column and add a few rows into it.
CREATE TABLE emp_jsonb(emp_id int NOT NULL, data jsonb);
INSERT INTO emp_jsonb VALUES (1, '{"name": "John", "hobbies": ["Movies", "Football", "Hiking"]}');
INSERT INTO emp_jsonb VALUES (2, '{"name": "John2", "hobbies": ["Diving", "Football", "Hiking"]}');
INSERT INTO emp_jsonb VALUES (3, '{"name": "John3", "hobbies": ["Cycling", "Football", "Hiking"]}');
INSERT INTO emp_jsonb VALUES (4, '{"name": "John4", "hobbies": ["Reading", "Football", "Hiking"]}');Step 9. Create a replication slot with the following SQL statement.
CREATE PUBLICATION emp_jsonb_pub FOR TABLE public.emp_jsonb where (data -> 'name' = '"John3"');Step 10. Change the name of the replication slot as shown in step 6. At these moment, the replication slot name is "emp_jsonb_pub".
Step 11. Re build and run the App.java again.
Step 12. Add a new row in Json
INSERT INTO emp_jsonb VALUES (5, '{"name": "John3", "hobbies": ["Cycling1", "Football", "Hiking"]}');In the application console, you should get a new message like these:
[main] INFO com.blu.repl.App - [CDC event]: {"tupleData":{"data":"{\"name\": \"John3\", \"hobbies\": [\"Cycling1\", \"Football\", \"Hiking\"]}","emp_id":5},"relationName":"public.emp_jsonb","type":"insert"} It's enough for now, all the DML/DDL scripts is available on the GitHiub project.
Resources:
PostgreSQL output plugin list https://wiki.postgresql.org/wiki/Logical_Decoding_Plugins
PostgreSQL logical decoding concept.
Physical and Logical replication API https://access.crunchydata.com/documentation/pgjdbc/42.1.1/replication.html